API Rate Limiting — Part 1

Whether you build public API open for developers or internal API for your apps, you might have heard of the term rate limiting or throttling, here is a quick explanation as I understand it.
What
Rate limiting is controlling the number of requests getting through your app in specific interval of time, a way of controlling usage as you never want to leave your API open to unlimited number of concurrent requests, here is why:
Why
- Security speaking, limiting will protect you against spammers and denial of service (DDoS) attacks or at least will minimize the danger of overloading the system with infinite number of requests in short time which can cause a down time.
- Performance is what you would care about when building public API which anyone can use, you need to be ready for your awesome API getting popular and attracting many developers to use it, this means not letting high number of requests getting in the way of your API being fast and reliable, or else developers using your API will probably churn searching for a better alternative.
- More Scalable API, when you regulate usage, your API can handle more users and thus scale your business with minimum infrastructure cost.
If you find this describing your use case, here is how you can use a limiter:
How
There is many ways to use rate limiters but here are three levels rate limiters can be used:
- General: this means we’ll threshold overall requests to some limit regardless of your API resources (endpoints) or entities (user or ip or business entities in your API).
- Granular: apply different rates on different resources, for example: apply 5 requests per minute on login endpoint (to minimize brute force maybe), but apply 10 requests per minute on show restaurants endpoint (in your awesome food delivery API).
POST: api.awesome.com/login // 5 requests/minute overall
GET: api.awesome.com/resturants // 10 requests/minute overall
- Granular per entity: applying rates differently per business entity per a resource, for example: you can limit each user to make a maximum of 5 requests per minute. which is different from just limiting the endpoint overall for all users, this will allow your API to grow normally and only limit the abusive usage.
// Per User
POST: api.awesome.com/login // 5 requests/minute for user1
GET: api.awesome.com/resturants // 10 requests/minute for user1
Rate limiting can be implemented on the web server level ex: nginx, but if the limit is specific to a business entity you have to do it on the application level.
the rate limiter logic might look easy but it can sometimes be tricky, specifically when it comes to using in in horizontally scaled distributed system, so here is some standard strategies on how to implement it:
Strategies
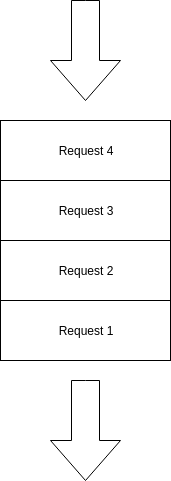
Leaky Bucket
Imagine a water bucket with few holes that people keep filling water into it, you’ll notice water level is increasing in a constant rate, till the bucket is full, And now any new water drops will just overflow the bucket and won’t make it inside the bucket.
This is exactly what this algorithm do, a FIFO Queue with a constant capacity and if average rate of requests exceeds the rate limit you set, then the requests will overflow and the new requests are just dropped and not processed, for example that’s a full 4 sized requests queue, any new requests at that point will just get dropped, till there is a space free in the queue.
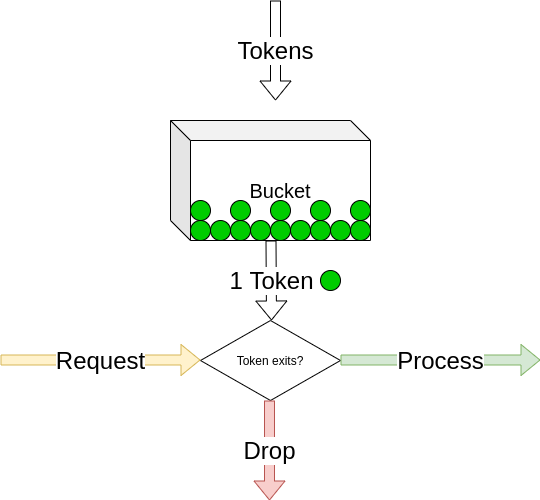
Token Bucket
This type of algorithms can be applied per entity, so let’s say we’ll apply this algorithm per unique user, here a new concept of tokens is introduced, and the idea is that the request needs a token to be processed, if no token it’ll be dropped, here is how it works.
For each unique user :
- we record tokens count.
- we record the last request timestamp.
Then for each new request the user makes we get their record and do three things:
- increment tokens count depending on difference between now and last Timestamp.
tokens += number_of_minutes * limit_per_minute
- if tokens count is zero, then we drop the request (don’t process).
- decrement tokens count and update timestamp.
For example with a rate of 2 requests per minute
// rate = 2
// last request time is 09:58:44
// "user_1": { "tokens": 1, "ts": 1490000000 }
// new request at 10:00:23
// (minutes difference between now and last ts) * rate = 4 tokens
// then 4 + 1 = 5 tokens, not zero so we can process the request ✔
// decrement tokens so it's ️5 - 1 = 4 tokens
=> "user_1": { "tokens": 4, "ts": 1490000001 }
// new request at 10:00:42 at same minute ✔
=> "user_1": { "tokens": 3, "ts": 1490000002 }
// new request at 10:00:49 at same minute ✔
"user_1": { "tokens": 2, "ts": 1490000003 }
// new request at 10:00:52 at same minute ✔
"user_1": { "tokens": 1, "ts": 1490000004 }
// new request at 10:00:55 at same minute ✔
"user_1": { "tokens": 0, "ts": 1490000005 }
// new request at 10:00:59 at same minute, 0 tokens so we won't process this request (DROP) ❌
"user_1": { "tokens": 0, "ts": 1490000005 }
Drawbacks
Despite the simplicity and clean design of the algorithm, when using it with shared memory like REDIS in distributed environment it’s not race condition safe due to reading first then writing the tokens count, the solution to this would be using locks which would solve the problem on the expense of latency of requests.
In part 2 we'll discuss more strategies, will be published soon.
Please leave a comment if you have any thought about the topic
Thanks for reading ❤️